Weekly post already? But it seems like the last one was just the other day! It’s true, it has been less than a week since the last one, but I feel like the weekend is a good time for me to write these so you’re getting another update. This post is going to be very tech heavy. So I’m going to put the less tech heavy stuff in the next couple paragraph or so, then I’m going to explain my implementation for educational purposes.
I’m currently reading Game Engine Architecture by Jason Gregory and one of the early chapters focused on development tools and how important they are. My previous full time job was building development tools for web developers so I’ve already developed an appreciation for having them. Also, you may remember my last post where I talked about debugging tools I’ve added to my game.
Games require a lot of thought and consideration to the performance of the code that is written and one of the primary metrics that the game industry uses is FPS, or Frames Per Second. This is the number of times the full screen is rendered to the screen per second. A common standard for this is 60FPS which is what most “high definition” monitors and TVs can produce. Because the frames need to be roughly evenly spaced it means that each frame gets about 16.6 milliseconds to be fully calculated and rendered.
So, I built a tool to let me analyze the amount of time each frame took to render. I knew I’d want to graph the data, and I didn’t have the ability to make graphs using my game engine. I don’t even have the ability to display text. So I went with a setup called Electron to let me use the sort of code and techniques I use for web development and am very familiar with. And this screenshot is the results:
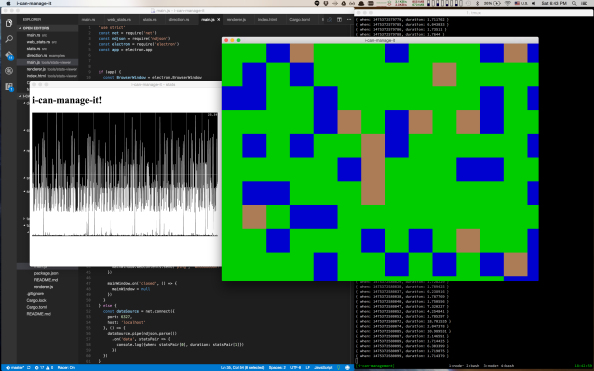
In the background is my text editor with some code, and a bunch of debug information in my terminal. On the right with the pretty colors is my game. It is over there rendering about 400-450 FPS on my mac. On the left in the black and white is my stats viewer. Right now it just shows the duration of every frame. The graph dynamically sizes itself, but at the moment it was showing 2ms-25ms range. Interesting things to note is that I’m averaging 400FPS but I have spikes that take over 16.6ms, so the frames are not evenly spaced and it looks like ~58FPS.
Ok, that’s the tool I built and a brief explanation. Next, I’m going to go into the socket server I wrote to have the apps communicate. This is the very tech heavy part so friends just reading along because they want to see what I’m up to, but aren’t programmers, this is the time to hit the eject button if you find that stuff boring and you kinda wish I’d just shut up sometimes.
To start with, this gist has the full code that I’ll be talking about here. I’m going to try to use snippets cut up with text from that, so you can refer to that gist for context if needed. This is a very simple socket server I wrote to export a few numbers out of my engine. I expect to expand this and make it more featureful as well as bidirectional so I can opt in or out of debugging stuff or tweak settings.
Lets first look at the imports, I say as if that’s interesting, but one thing to note is I’m not using anything outside of std for my stats collection and socket server. Keep in mind this is a proof of concept, not something that will need to work for hundreds of thousands of users per second or anything.
use std::io::Write;
use std::net::TcpListener;
use std::sync::mpsc::{channel, Receiver, Sender};
use std::thread;
I’ve pulled in the Write trait from std::io so I can write to the sockets that connect. Next up is TcpListener which is the way in the standard library to listen for new socket connections. Then we have channels for communicating across threads easily. Speaking of threads, I pull in that module as well.
Ok, so now that we know the pieces we’re working with, lets talk design. I wanted to have my stats display work by a single initializing call, then sending data over a channel to a stats collection thread. Because channels in rust are MPSC channels, or Multiple Producer Single Consumer channels, they can have many areas sending data, but only 1 thing consuming data. This is what lead to the interesting design of the initializing function seen below:
pub fn run_stats_server () -> Sender<Stats> {
let (stats_tx, stats_rx) = channel();
thread::Builder::new()
.name("Stats:Collector".into())
.spawn(move || {
let new_socket_rx = stats_socket_server();
let mut outputs = vec![];
while let Ok(stats) = stats_rx.recv() {
while let Ok(new_output) = new_socket_rx.try_recv() {
outputs.push(new_output);
}
let mut dead_ones = vec![];
for (number, output) in outputs.iter().enumerate() {
if let Err(_) = output.send(stats) {
dead_ones.push(number);
}
}
for dead in dead_ones.into_iter() {
outputs.remove(dead);
}
}
})
.unwrap();
stats_tx
}
Let’s work our way through this. At the start we have our function signature,
run_stats_server is the name of our function, it takes no arguments and returns a Sender channel that sends Stats objects. That channel is how we’ll export data from the engine to the stats collector. Next we create a channel, using common rust naming of tx or “transmit” for the Sender and rx for Receiver sides of the channel. These will send and receive stats objects so we’ll name them as such.
Next, we start building up the thread that will house our stats collection. We make sure to give it a name so stack traces, profilers, and other development tools will be able to help us identify what we are seeing. In this case, Stats:Collector. We spawn the thread and hand it a special type of function called a closure, specifying that values it uses from the function creating the closure, should become owned by the closure via the move flag.
We’re going to skip the implementation of stats_socket_server() for now, except to note that it returns a Receiver<Sender<Stats>> which the receiving side of a channel that will contain the sending side of a channel containing stats objects. Oooph a mouthful! Remember the “interesting” design, this is the heart of it. Because, I could have any number of clients connect to the socket over the life of the app, I needed to be able to receive from a single channel on multiple threads. But if you recall above, channels are single consumer. This means I have to spread the messages across multiple channels myself. Part of that design means anytime a new connection comes in, the stats collection service gets another channel to send to.
We make some storage for the channels we’ll be getting back from the socket server, then launch into our loop. A reader may notice that the pattern while let Ok(value) = chan_rx.recv() {} is littered all over my code. I just learned of this and it is terribly useful for working with channels. You see, that stats_rx.recv() call in the code above? That blocks the thread until something is written to stats_tx. When it does return a value, that value is a result that could be Ok<T> where T is the type of the channel, or Err<E> where E is some error type.
Channels will return an Err when you try to read or write to them and the other side of the channel has been closed. Generally when this channel fails it is because I’ve started shutting down the main thread and the Stats:Collector thread hasn’t shut down yet. So as long as the channel is still open, the server will keep running.
Once we get past this while let we have a new Stats object to work with. We check to see if any new connections have come in and add them to the outputs vector. We do it in this order because new connections only matter if there is new data to send to them. We aren’t sending any history. Notice how this loop uses try_recv() instead of recv()to get messages from the channel. This is because we don’t want to wait for a message if there isn’t any, we just want to check and keep going instead. The try version of the function will immediately return an Err if there are no messages ready.
We make a vector to hold onto the indices of the dead channels as we try to send the stats payload to each of them. Since channels return errors when the other side has closed, we close the socket’s side of the channel when the socket closes, letting it cascade the error to here. We then collect the index so we can remove it later. We can’t remove it now since we’re accessing the vector, and rust ensures that while something is reading the data, nothing can write to it. Also, a note, when you use a channel’s send function it takes ownership of the object you are sending. Since my stats objects are pretty small and simple I made them copiable and rust is automatically creating a copy for each outgoing channel.
In the last part of the loop, we do a quick pass to clean up any dead channels. The only other things of note in this function are that the thread creation uses .unwrap() as a deliberate choice because thread creation should never fail, if it does, the application is in some state we didn’t account for and should crash, probably low memory or too many threads. Then finally it returns the stats_tx we made at the top.
Now we get to the other function that makes up this stats collector and server. The goal of this function is to listen for new socket connections and return channels to send to them. Without further adieu here it is:
fn stats_socket_server() -> Receiver<Sender<Stats>> {
let (new_socket_tx, new_socket_rx) = channel();
thread::Builder::new()
.name("Stats:SocketServer".into())
.spawn(move || {
let server = TcpListener::bind("127.0.0.1:6327").unwrap();
let mut connection_id = 0;
for stream in server.incoming() {
if let Ok(mut stream) = stream {
let (tx, rx): (_, Receiver<Stats>) = channel();
new_socket_tx.send(tx).unwrap();
thread::Builder::new()
.name(format!("Stats:SocketServer:Socket:{}",
connection_id))
.spawn(move || {
while let Ok(stats) = rx.recv() {
let message = format!("[{},{}]\n",
stats.when,
stats.duration)
.into_bytes();
if let Err(_) = stream.write(&message) {
// Connection died;
break;
}
}
})
.unwrap();
connection_id += 1;
}
}
})
.unwrap();
new_socket_rx
}
We’ve already discussed the function signature above, but now we’ll get to see the usage of the Sender side of at channel sending channel. Like our first function, we immediately create a channel, one side of which new_socket_rx is returned at the bottom of the function. The other we’ll use soon.
Also familiar is the thread building. This time we name it Stats:SocketServer as that is what will be running in this thread. Moving on, we see TcpListener show up. We create a new TcpListener bound to localhost on port 6327 and unwrap the value. We create a counter we’ll use to uniquely track the socket threads.
We use the .incoming() function much the same way as we use the .recv() function on channels. It will return an Ok<TcpStream> on successful connect or Err<E> when an error happens. We ignore the errors for now and grab the stream in the success case. Each stream will get its own channel so we create channels, simply named tx and rx. We send tx to over new_socket_tx which is connected to the channel sending channel we return.
We build yet another thread, 1 thread per connection would be wasteful if I planned on having a lot of connections, but since I’ll typically only have 0-1 connection, I feel like using a thread for each isn’t too expensive. This is where we used that connection_id counter to uniquely name the thread. Because we may have multiple of these at the same time, we make sure they are named so we can tell them apart.
Inside the thread, we use the now familiar pattern of using .recv() to block and wait for messages. Once we get one, we format it as a 2 element JSON array with a newline on the end. I didn’t want to worry about escaping or using a full JSON serialization library, so I just wrote the values to a string and sent that. The reason for the newline is so the receiving side of the socket can treat it as a “newline delimited JSON stream” which is a convenient way to speak across languages. We note if there is an error trying to write to the socket, and if so, break out of our loop.
The rest is just a little bookkeeping for tracking the connection_id and returning the channel sending channel. While this description has gotten pretty long, the implementation is relatively simple. Speaking of things to build out with time, the last bit of code we’ve not discussed for there rust side of this. The Stats struct.
#[derive(Clone, Copy, Debug)]
pub struct Stats {
pub when: u64,
pub duration: u64
}
The reason I didn’t mention it sooner, is it is pretty boring. It holds onto two u64 which are unsigned 64bit integers, or whole positive numbers, that I send over the wire. With time this will certainly grow larger, not sure in what ways though. I could have used a 2-tuple to hold my stats like (u64, u64) instead of a struct. As far as I know they are just as memory efficient. The reason I went with a struct though was for two attributes. First it is a name that I can change the contents of without having to change code everywhere it passes through, just where the struct is created or accessed. If I add another u64 to the tuple above, the function signatures and the points where the data is created and accessed need to change.
The other reason is proper use of the type system. There are many reasons to create a (u64, u64) that have nothing to do with stats, by creating a type we force the API user to be specific about what their data is. Both that the positions of the data are correct by referencing them by name, and because they are in a container with a very specific name. Granted, I’m the API user as well as implementer, but in 6 months, it may as well been implemented by you, for how familiar it’ll be to me.
The electron side of this is actually pretty boring. Because JS is built to work well with events, and this data comes in as a series of events, I basically just propagate them from the socket connection to electron’s IPC, or Inter Process Communication, layer which is one of the first things folks learn when making electron apps. For the graph I used Smoothie and basically just copied their example code and replaced their call to Math.random() with my data.
This project was meant to be the start of development tools for my game engine. A proof of concept for having those tools be external but hooked up via a socket. Next steps will be making the data presentation nicer, possibly making it two way so I can see what debugging tools are enabled and change those settings from this tool, and many other things.
I really hope that this explanation of some rust code was fun and helpful. If you have questions, feel free to ask. Keep in mind this tool and code are not meant to be a bullet proof production used by many people thing, but more just an exploration of a brain worm I had. While I’m keeping most of my source private, all the source shown here should be considered under the ISC license which basically says do whatever with it and don’t blame me if it turns out to be terrible.
 :
: